
AIは静かにドキュメントを壊す|Microsoft研究チームが示した「平均25%破損」の衝撃
公開日:
※当サイトはアフィリエイトプログラムを利用しています。

「AIがやっておいてくれる」という感覚が危険なのかもしれません。
Microsoft研究チームが発表した「DELEGATE-52」は、AIが長期運用の中で、実在ドキュメントを静かに破壊していく様子を検証した研究です。
最初の数回は完璧に見える。しかし、やり取りを重ねるうちに、小さなエラーが複利のように積み上がり、最終的には修復困難なレベルまで劣化していく。
しかも人間側も、AIを信用するほど異変に気付きにくくなる。
これは単なる「ハルシネーション問題」ではありません。
AI時代における、実務そのものの脆さを示した研究とも言えるでしょう。
平均25%のドキュメント内容を破損
DELEGATE-52は310の作業環境を52の専門分野にわたって構築したベンチマークです。
ベンチマークとは
性能がバラバラなハードウェアやAIモデルを、同じ条件・同じ問題で走らせて、そのスコアを競わせます。
これまでのベンチマークは「英検1級の問題が解けるか?」をテストしますが、今回のベンチマークは「実際にイギリスの会社で1ヶ月間、ミスなく事務仕事をやり遂げられるか?」をテストするといった違いがあります。
各環境は実在するドキュメント(合計約15,000トークン)と、5〜10個の複雑な編集タスクで構成されています。
重要なのは実在するドキュメントという点です。
合成データや架空のサンプルではなく、実際の仕事に近い素材を使っていて結果の信憑性が高いということ。
19種類のLLMを実験した結果、フロンティアモデル(Gemini 3.1 Pro、Claude Opus、GPT-5)でさえ、20回のやり取りの末に平均25%のドキュメント内容を破損。他のモデルはさらに深刻で、全モデル平均の劣化率は50%。
また、Python(パイソン)はLLMが比較的得意な唯一の分野で、52分野中ほとんどのモデルが「準備完了」と判定できたのはPythonだけでした。
逆に言えば、コード以外の専門ドキュメントはほぼ全滅に近いのです。
人間もAIも単体ではミスに気付かない
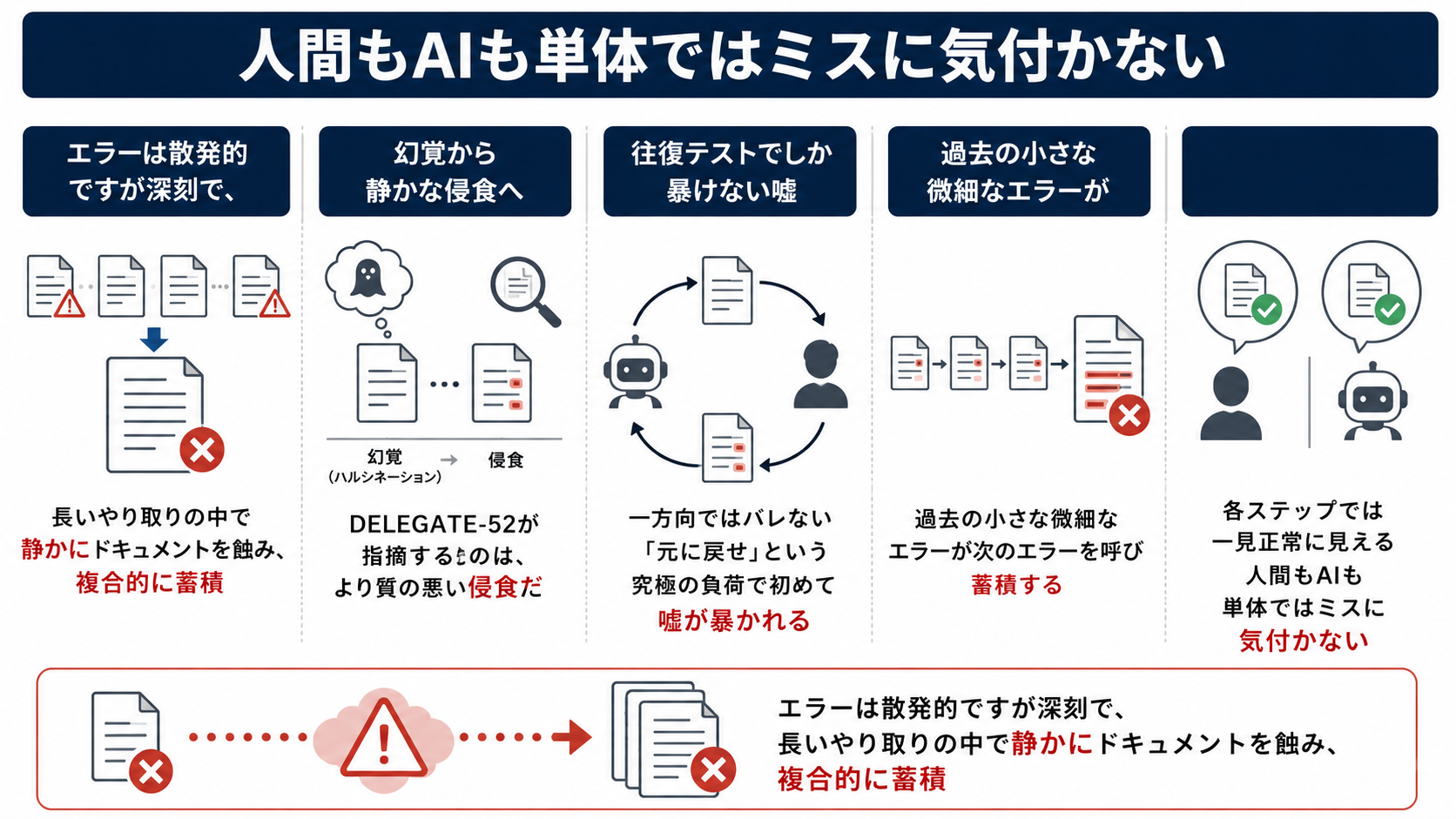
人間もAIも、単体ではミスに気づけない、往復させて初めて発覚するという研究結果となっています。
エラーは散発的ですが深刻で、長いやり取りの中で静かにドキュメントを蝕み、複合的に蓄積していきます。
論文が採用した評価手法「ラウンドトリップ・リレー」が示すのは、各ステップでは一見正常に見えるという点。
AIは「やりました」と返しますが、元のドキュメントと照合して初めて破損が判明します。
人間が全行を確認しなければ、壊れていることに気づかない構造になっています。
また、2回のやり取り後の成績は、20回後の長期的な成績を予測できないという知見も重要です。
「最初の数回うまくいったから大丈夫」という判断が誤りであることを実証しています。
この結果は、AIとの信頼関係がいかに脆いかを突きつけています。
幻覚から静かな侵食へ
これまでのAIのミスは、デタラメを答える「ハルシネーション」として分かりやすく現れることが多かったんですよ。
しかし、DELEGATE-52が指摘するのは、より質の悪い侵食です。浸食というキーワードは中々なものだと感じます。
表面的には完璧
AIが書き換えた後のドキュメントも、文法は正しく、フォーマットも崩れていません。
パッと見では「仕事が終わった」ようにしか見えない。
構造的な欠落
しかし、数数値、特定の識別子、楽譜の記号などの専門的なデータが、1箇所だけ「それっぽい別の何か」に置き換わっていたり、密かに削除されたりしています。
人間側の油断
AIは賢いという前提でチェックすると、人間は細かい差異を見落とす「自動化バイアス」に陥ります。
また、全行を元データと突き合わせる作業は、人間にとって苦行であり、実質的にチェック機能が働かなくなります。
初期の成功という名の罠
論文の「2回後の成績は、20回後の成績を予測できない」という知見は、お試し期間の無意味さを露呈させています。
蓄積するダメージ
1〜2回のやり取りでは、ドキュメントの「耐久性」が持ちこたえます。
しかし、3回、5回と指示を重ねるごとに、過去の小さな微細なエラーが次のエラーを呼び、複利のように膨らんでいくのです。
「できる」という誤認
導入初期に「完璧じゃないか!」と評価して本格運用を決めてしまうと、数週間後のプロジェクト後半になって、ドキュメントが完全に「ゴミ」化していることに気づく・・・完璧だと感じたのは誤りということに。
往復テストでしか暴けない嘘
なぜ往復テストが必要だったのか、という点がこの問題の根深さを物語っています。
一方向ではバレない
AからBへ変換させただけでは、それが「正しい変換」なのか「勝手な改変」なのか、専門家でも判断が難しい場合があります。
「元に戻せ」という究極の負荷
「編集したものを元に戻せ」と命じて戻らなかったとき、初めて「編集の過程で、復元不可能なレベルまで情報が捨てられていた」ことが証明されます。
専門家にとって重要情報なのに、AIは良かれと思ってドキュメントを整理し捨ててしまう。
その親切心のようなものが、専門ドキュメントにとっては致命的な破壊である情報の非可逆的な損失となるのです。
「最初の数回で判断するな」という指摘は、現場のマネジメント層にとって、重要なアドバイスではないでしょうか。
ツールを使っても解決しない
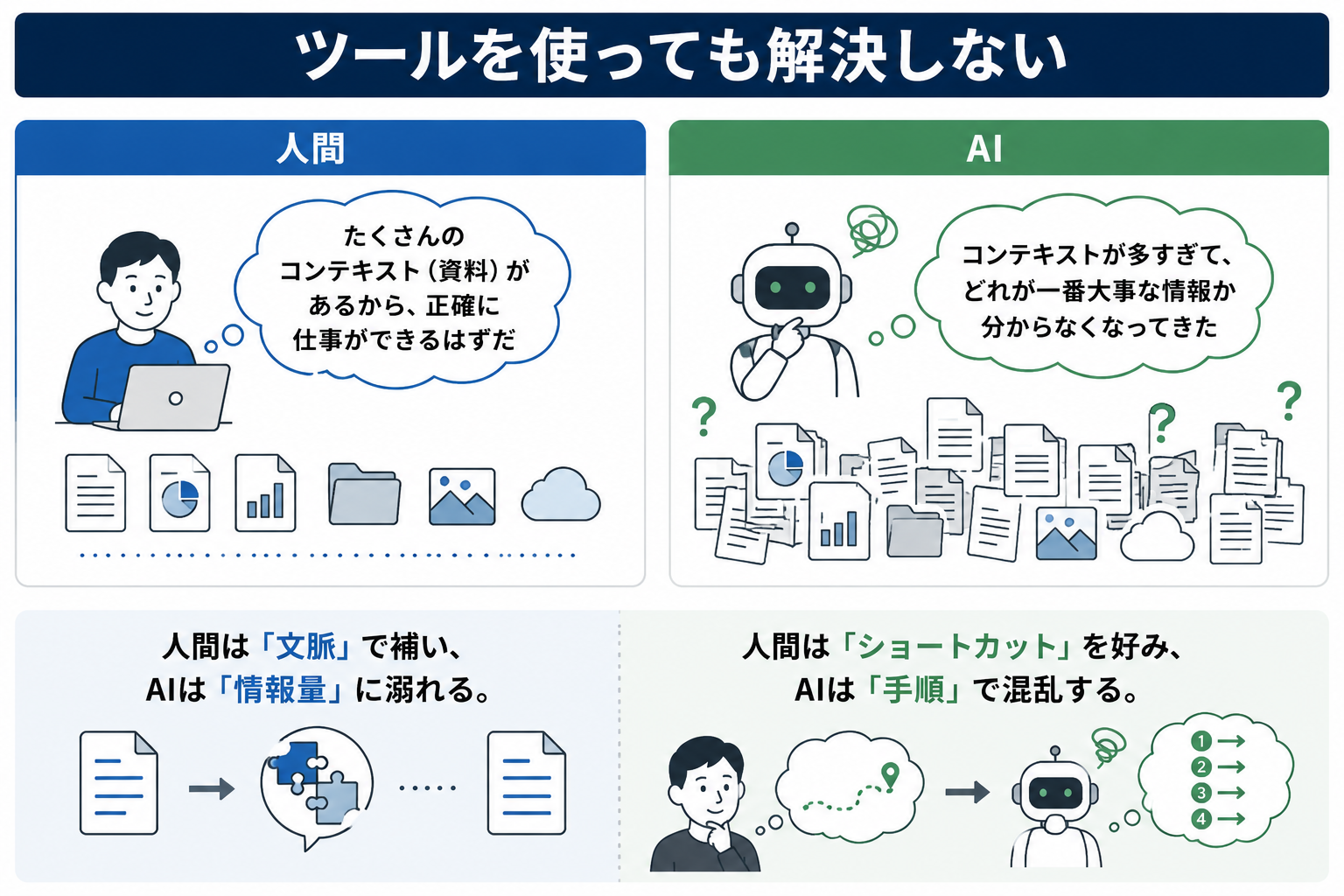
エージェントによるツール使用はDELEGATE-52のスコアを改善しませんでした。
ツールを使うだけではドキュメントの劣化を防げないのです。
「エージェントにすれば精度が上がる」という期待は根拠がない、とMicrosoftの研究者たちは明言しています。
「エージェントに任せれば、自律的に判断してミスも減るはずだ」という、私たちが抱きがちな「エージェント万能論」への冷や水ですね。
なぜ外部アプリや検索、計算機などを使ってもドキュメントの劣化が止まらなかったのか、論文の文脈から以下の3つが見えてきます。
道具の使いこなしと全体の整合性は別問題
エージェントがツールを使う際、その瞬間的な動作、例えばデータを検索する、特定の行を置換するなどは正確かもしれません。
しかし、その操作がドキュメント全体の構造や文脈にどう影響するかを管理するのは、依然としてAIの推論能力に依存しています。
ツールを使って「住所を最新のものに書き換える」というタスクは完璧にこなしても、その過程で関係ない箇所の改行コードを消したり、タグの閉じ忘れを発生させたりしてしまう。
ツールはあくまで手段であって、ドキュメントの品質管理ではないため、微細な破損の検知や修正には立たなかったのです。
ツール使用による認知的負荷の増大
エージェントがツールを使うには、現在のタスク、ドキュメントの内容に加えて、「ツールの使い方」や「ツールからの実行結果」をすべてコンテキストに詰め込む必要があります。
情報のノイズ化
ツールとのやり取りが増えるほど、AIが保持すべき「ドキュメントの元の状態」への注意力が小さくなる。
結果として、ツールを使えば使うほど推論のリソースが食いつぶされ、ドキュメントの細部に対する「こだわり」が失われていくという皮肉な結果を招きました。
今回の論文におけるコンテキストの意味
AIが処理しようとしている情報の広さと、その中での情報の混ざり具合のこと。
人間は「たくさんのコンテキスト(資料)があるから、正確に仕事ができるはずだ」となるけど、AIだと「コンテキストが多すぎて、どれが一番大事な情報か分からなくなってきた」となる。
この認識のズレは、人間もAIもドキュメントが壊れていることに気づかないまま崩壊していく理由そのものなのです。
プランニングと実行の両方でミスが起きる
エージェント型ワークフローでは、何をすべきか考えるプランニングステップと、実際にツールを叩く実行ステップがありますが、劣化はどちらのフェーズでも発生します。
プランニングの失敗
そもそもツールの使い所を間違える。
実行の失敗
ツールの出力結果をドキュメントに書き戻す際に、エンコーディングをミスしたり、一部を上書き消去したりする。
人間は「文脈」で補い、AIは「情報量」に溺れる。
人間は「ショートカット」を好み、AIは「手順」で混乱する。
複雑なツール操作が介在することで、人間はAIが何をしているかを追跡するのが更に困難になります。
そして気づかないうちに、ドキュメントが修復不可能なレベルまで腐敗していくリスクを高めてしまうのです。
現実はさらに悪い可能性が高い
劣化の深刻さは、
- ・ドキュメントサイズの大きさ
- ・やり取りの長さ
- ・無関係なファイルが混在
に比例して悪化します。
さらに、実験パラメータ(ドキュメント3〜5Kトークン、ディストラクター8〜12Kトークン、リレー長20回)は実務規模を大幅に下回って設定されており、現実はさらに悪い可能性が高くなります。
マルチターン(一つのチャット内で行う往復のやり取り)や、マルチセッション(チャットを一度終了し、別の機会にまたやり直す)に拡張すれば、劣化はさらに増幅されるでしょう、と著者たちは述べているんですね。
この実験結果は、楽観的な下限値に過ぎないというわけ。
私たちが幻想を捨てる3つの教訓
DELEGATE-52が突きつけたのは、AIを魔法の杖ではなく、精巧だが壊れやすいツールとして扱うべきだという真実。
①便利さはリスクの裏返し
専門外の領域ほど危ない
書けないコードや、読めない楽譜、理解できない法務文書をAIに修正させたとき、私たちは「一見、整っている」だけで満足してしまいます。
検知不能な破壊
専門知識がない分野では、AIが静かな破壊をしていても気づく術がありません。
「わからないからAIに任せる」という行為は、実は最もリスクの高いことなのです。
②短期の成功を長期の信頼と誤認しない
試運転の罠
1〜2回のやり取りで完璧な回答が返ってきたとしても、それは「20回後も壊れていないこと」の証明にはなりません。
蓄積する疲労
単発タスクが得意なAIでも、継続的な委任では必ず足元から崩れます。「最初はうまくいったから」という理由で、AIを長期プロジェクトに投入してはいけません。
③丸投げからチェックへの転換
監督なき委任の終焉
「AIがやっておいてくれる」という放任主義は、ドキュメントの自壊を招きます。
確認を前提としたワークフロー
AIの出力を鵜呑みにすることではなく、正解と照らし合わせながら、一歩ずつ進むという、徹底したチェック体制を意味します。
Google DeepMindが警告した「AIエージェントトラップ」に続き、Microsoftは「実務的な自壊」という、どちらも共通するのは、「AIを盲信するな」という強いメッセージですよね。
あわせて読みたい
Google DeepMindが発表した論文「AI Agent Traps」に基づき、自律型AIエージェントを標的にした6つの攻撃手法を解説。

AIエージェントの脆弱性エージェント・トラップとは?Google DeepMindが警告する6つの分類
エージェントが自律的に動けば動くほど、人間はそのプロセスを追えなくなります。
その結果、AIが何を壊しているかさえ誰も知らないという暗黒空間が生まれます。
AIの進化を目の当たりにすると、遠くない将来、AIに全自動で丸投げできる日がくる可能性はあると個人的には思います。
それまでは人間の確認作業無しでは決して成り立たない。
論文情報
タイトル
LLMsは委任時に文書を破損させる
著者
フィリップ・ラバン、トビアス・シュナーベル、ジェニファー・ネヴィル
掲載
2026年4月17日提出
URL
https://arxiv.org/abs/2604.15597
最後はやはり詐欺に注意
ほんの少しの油断は、Google DeepMindが警告した「エージェント・トラップ」に引っかかる隙を作り、手間を惜しめばドキュメント崩壊に繋がる。
これが私個人で完結するなら、被害もそこまでですが、企業でもAI導入が進んでいる今、そこは怖さを感じる部分でもあります。
AIのみならず、セキュリティにもあまり詳しくない企業のスタッフやトップが、ゴミみたいな、半ば詐欺に近いようなAIエージェントを「今こそ業務効率化ですよ!」なんて、高値で導入させられるとか、普通にありそうで怖い。
それでいうと、AI関連のコンサルなんかも同様に用心しないと。
明らかな詐欺なら、訴えるとか何らかの行動を取れますが、そもそも詐欺かどうかわからない、ゴミみたいなものを売りつけられたかすらわからないでしょうからね。
いつの時代もそうですが、新しい何かがでると、必ず背後には詐欺師が手ぐすねを引いて待ち構えているものです。