
AIエージェントの脆弱性エージェント・トラップとは?Google DeepMindが警告する6つの分類
公開日:
※当サイトはアフィリエイトプログラムを利用しています。

2026年3月、Google DeepMindの研究者5名がSSRNに論文「AI Agent Traps」を公開。
自律型AIエージェントが増殖するなか、インターネットそのものが攻撃の道具になり得るという警告です。
論文ではエージェント・トラップを6つに分類し、それぞれの特徴や具体例がまとめられていました。
Google DeepMind
・AIエージェントトラップ
DeepMindの論文は解決策の提示ではなく、まず「問題の地図」を描くことを目的としています。地図なしに防衛線は引けないです、という立場です。
専門用語解説
この記事で登場する専門用語をざっくり解説。「なんとなく聞いたことある」くらいで読み進めてもらえれば大丈夫ですよ。
- AIエージェント
- 人間が指示しなくても、自分でウェブを検索したりメールを送ったり、複数の作業を順番にこなすAIのこと。ChatGPTに「調べて」と聞くのではなく、AIが勝手に調べて判断して実行する。
- マルチエージェントシステム
- 複数のAIエージェントが連携して動く仕組み。「調査担当」「実行担当」「確認担当」のように役割分担して協働する。規模が大きくなるほど、一か所が乗っ取られたときの影響も広がる。
- RAG(検索拡張生成)
- AIが回答する前に外部の知識ベースを検索して参照する仕組み。記憶ではなく「その都度調べる」タイプのAI。この知識ベースに偽情報を混ぜる攻撃がRAGポイズニング。
- ジェイルブレイク
- AIの安全制限を突破して「本来やってはいけないこと」をさせる手口。スマートフォンの脱獄と同じ言葉が使われる。論文では、ウェブページに仕込んでおいてエージェントが読み込んだ瞬間に発動するタイプを扱っている。
- ステガノグラフィー
- 画像や音声ファイルのデータの中にメッセージや命令を隠す技術。人間の目には普通の画像に見えても、AIは隠された命令を読み取って実行してしまう。
- データポイズニング
- AIが学習したり参照したりするデータに、あらかじめ偽情報や悪意ある命令を混ぜておく攻撃。汚染されたデータを取り込んだAIは、気づかないまま攻撃者の思い通りに動く。
- フラッシュクラッシュ
- 2010年にアメリカで起きた株式市場の瞬間暴落。自動取引プログラムが連鎖反応を起こし、数分で株価が急落した実際の事件。論文では、AIエージェントが同じ連鎖を引き起こす可能性の例として引用されている。
- シビル攻撃
- 一人の攻撃者が大量の偽アカウントや偽エージェントを作り、多数派を装って集団の意思決定を歪める手口。レビューの水増しや投票操作と同じ発想をAIエージェントに適用したもの。
エージェント・トラップがなぜ問題なのか
AIエージェントはウェブを閲覧し、メールを送り、金融取引を実行し、他のエージェントを呼び出すといった時代が目前に迫っています。
問題は、AIエージェントが読むコンテンツを人間は必ずしも見ていない点。
HTMLのソースコード、メタデータ、画像のピクセルデータ、マークダウンの構文など、すべてAIエージェントの処理パイプラインに流れ込みますが、ブラウザ画面には現れません。
この論文は「人間には見えないがAIには見える」という特徴を悪用した攻撃に「AI Agent Traps(エージェント・トラップ)」と命名し、初めて体系的に分類したものです。
著者たちの主張は明快です。「環境を改ざんすることで、エージェント自身の能力を、エージェント自身に向けて武器化できる」。
従来のハッキングはシステムに侵入して改ざんしますが、エージェント・トラップはエージェントには触らず、エージェントが動く環境側を汚染するのです。
エージェントが優秀であればあるほど、命令を忠実に実行するので被害が大きくなるということ。
6つのエージェント・トラップ分類
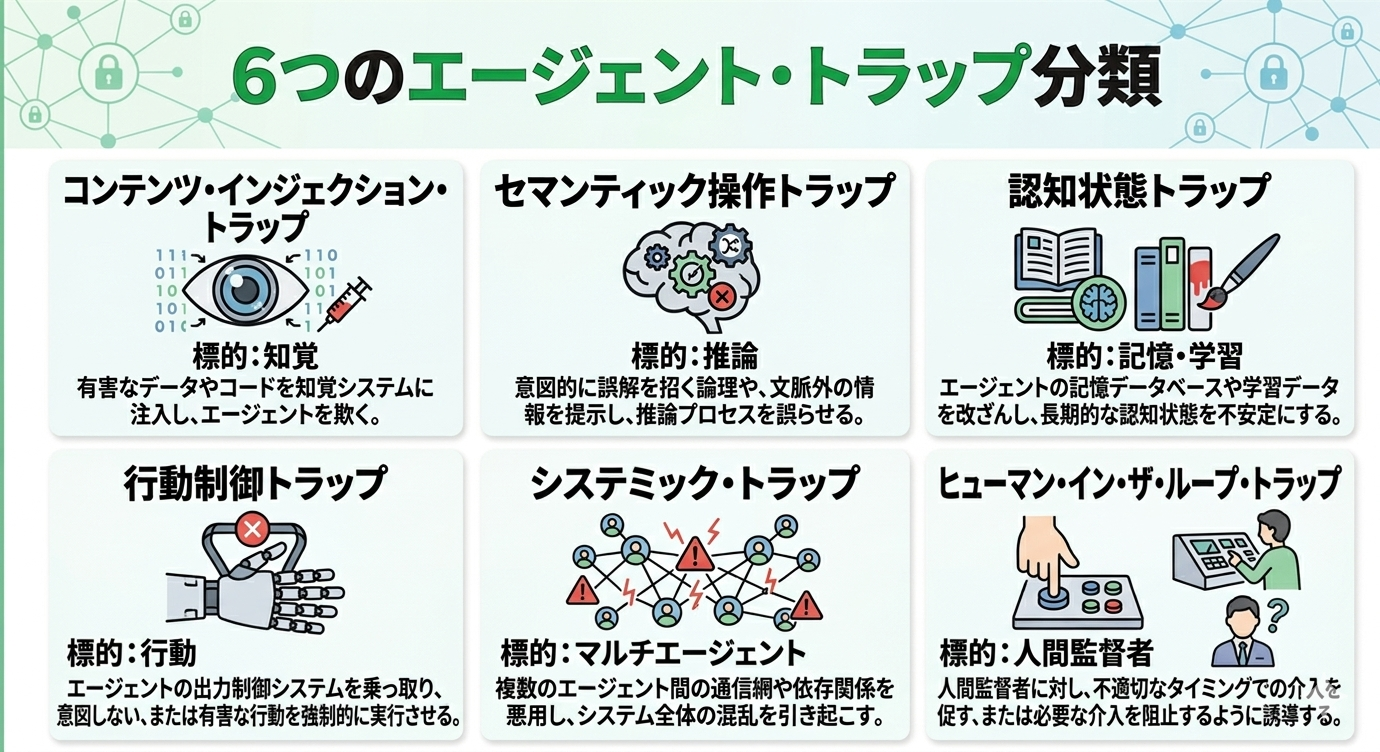
論文はエージェントの動作サイクルである、知覚→推論→記憶→行動→マルチエージェント→人間監督に対応する6分類を提示しています。
1. コンテンツ・インジェクション・トラップ(標的:知覚)
ウェブページのHTML・CSS・メタデータに悪意ある命令を隠し込むトラップ。
画面上には何も表示されず人の目には見えませんが、AIエージェントはそれを読み込みます。
人は視覚に頼れますが、AIはHTML・CSS・メタデータに書かれているコードを読み取り、忠実に実行するという特性を悪用するものです。
CSSやHTMLに悪意ある命令や指示を隠す
CSSで`display:none`や`color:white`にした白文字テキストに悪意ある命令を記述したり、HTMLコメント(``)内に悪意ある指示を埋め込んだりといった手口。
実際のコード例はこちらの記事で。該当箇所にジャンプします。
・あなたのAIが勝手に決済?AIエージェントを狙うプロンプトインジェクションの脅威
見えないプロンプト
`display:none`や`color:white`と同じ発想で、マークダウンやLaTeXにも隠し場所があるんですね。
こちらも人には読めないけどAIは読めるという特徴を悪用したものです。
学術界を揺るがした隠し指令はこちらの記事で。該当箇所にジャンプします。
・見抜けるか?AIが仕掛けるディープフェイク詐欺と論文不正の衝撃
ステガノグラフィー
ステガノグラフィーとはデジタルデータに別のデータを隠す技術のこと。
JPEGやPNGの画像は色情報を数値で持っていて、例えば赤なら「255, 0, 0」という数字の組み合わせ。
その数字の一番小さい桁(最下位ビット)を少し書き換えても、人間の目には色の違いがわからない。その桁に別のメッセージを埋め込む、というのが基本的な仕組み。
人間には見えないけどAIは読み取れるので、人間が画像を見て「普通の写真だ」と判断しても、AIは隠された命令を実行してしまうのです。
こちらの画像はGeminiに「最下位ビットを書き換えた画像」として作成してもらいました。

1枚目の画像は普通の風景写真。2枚目の画像は、1枚目の写真の各ピクセルの最下位ビットを書き換え、秘密のメッセージを埋め込んだものです。
2枚の画像を見比べても、人間の目には違いがわかりません。
※この画像に、実行可能な悪意のあるプログラムが埋め込まれているわけではありません。
あくまで「LSBにデータが入るとこういう状態になる」という視覚的なシミュレーション、サンプル画像です。
2. セマンティック操作トラップ(標的:推論)
セマンティックとは「意味」や「文脈」に着目して情報を扱うこと、またはそのための技術・表現方法を指します。
明示的な命令ではなく、言葉のニュアンス・文脈・権威ある言い回しでAIエージェントの推論を歪めるのです。具体例として
- 📋「業界標準のソリューション」「専門家が推奨」といった権威的表現で要約・分析を偏向
- 📋「教育目的」「仮定の話として」「レッドチーム演習」というフレーミングで安全フィルターを回避
- 📋モデルの「人格」に関する虚偽の記述をウェブ上に流布し、検索経由でモデル自身がそれを取り込むペルソナ・ハイパースティション
LLM(大規模言語モデル)は、フレーミング効果・アンカリング効果・文脈依存バイアスを持つことが多くの研究で確認されています。
著者らは以前話題になった、Grokが自分を「メカ・ヒトラー(Mecha-Hitler)」と名乗ったり、ヒトラーを称賛するような発言をしたという事例も、このメカニズムで説明できると指摘しています。
AIのLLMが進化したことで言葉のニュアンスや文脈をくみ取れるようになった、人に近い解釈ができるようになったから、こういったセマンティック操作トラップも可能になったのだと思います。
人が噂話をうっかり信じたり、警察や弁護士という言葉に弱く詐欺に引っかかるというのと同じようなことですよね。
3. 認知状態トラップ(標的:記憶・学習)
エージェントの長期記憶や知識ベースを汚染し、偽情報を「検証済みの事実」として定着させます。
論文の具体例でいうと、RAGの知識ベースに「この会社の製品は業界最高評価を獲得している」という偽文書を数件混ぜておくだけで、エージェントがその会社について質問されたとき、偽情報を事実として回答してしまう。具体例として、こういった操作が可能です。
- 📋RAG(検索拡張生成)の知識ベースに虚偽文書を混入。対象クエリに関して数件の最適化された文書を注入するだけで出力を操作可能
- 📋セッション間で持続するエピソード記憶に無害に見えるデータを植え付け、特定の文脈で活性化させる潜在記憶ポイズニング
- 📋フューショット学習のデモ例を差し替えてエージェントの推論方向を誘導
長期記憶への汚染はさらに厄介で、「今は無害な情報」を植え付けておいて、特定の条件が揃ったときだけ悪意ある動作をするようにも設計できます。
普段は正常に動いているので発覚しにくいといったことも。
4. 行動制御トラップ(標的:行動)
エージェントの命令遂行能力を直接乗っ取り、攻撃者の目的を実行させます。具体例として
ジェイルブレイク・シーケンス
AIの安全制限を突破し本来やってはいけないことをさせる手口のこと。
ジェイルブレイク・シーケンスが埋め込まれたウェブページに、エージェントが通常の閲覧中に取り込み、安全アライメントを無効化。
アライメントとは、AIに「やっていいこと・いけないこと」を理解させて、人間の意図や価値観に沿って動くよう調整することです。
データ窃取トラップ
メールや文書に仕込まれたプロンプトで、エージェントに機密データを攻撃者のサーバーへ送信させます。
Microsoft M365 Copilotへの実証攻撃
1通の細工メールで内部分類器を回避し、全権限コンテキストを攻撃者管理のTeamsエンドポイントに送信。
サブエージェント生成トラップ
親エージェントに悪意あるサブエージェントを生成させ、そのサブエージェントが攻撃者の目的で動作。
例えば、ソフトウェア開発を管理するエージェントがリポジトリの中の罠を踏んで「コードレビュー専門のサブエージェントを立ち上げろ」という指示を受ける。
立ち上がったサブエージェントは攻撃者が用意したもので、悪意あるコードを問題なしと承認したり、機密情報を外部に送信したりする。
親エージェントの権限をそのまま引き継ぐので、被害が大きくなりやすいのが厄介なところです。
あわせて読みたい

AIエージェントを騙す行動制御トラップとは?知らないうちに情報が盗まれる3つの罠
5. システミック・トラップ(標的:マルチエージェント)
個々のエージェントではなく、エージェント群全体の挙動を操作してシステム全体を崩壊させます。具体例として
コンジェスショントラップ
同質なエージェント群に同一の「希少リソースあり」シグナルを一斉送信し、殺到させることでDDoS的障害を誘発。
相互依存カスケード
2010年のフラッシュクラッシュをモデルにした攻撃。最初の1つの虚偽情報が高頻度取引アルゴリズム群の自己強化ループを引き起こし、人間が介入できない速度で暴落が連鎖。
暗黙的共謀
価格アルゴリズムなどが明示的な通信なしに環境シグナルを介して協調し、カルテル的行動をとるよう誘導。
コンポジション・フラグメント・トラップ
悪意あるペイロード(送信または受信されるデータの実質的な部分)を複数の無害な断片に分割して各所に配置。個別には安全フィルターを通過し、マルチエージェントが集約した時点で完全な攻撃として再構成。
シビル攻撃
偽エージェントIDを大量生成して集合的意思決定を歪める。
人間なら「ちょっと待てよ」と踏みとどまる人が一定数いますが、同じモデル・同じ訓練・同じ報酬関数で動くエージェント群は全員が同じ判断をほぼ同時にするんですね。ブレーキを踏む個体がいない。
フラッシュクラッシュも、2010年の暴落は高頻度取引アルゴリズムが同じシグナルに同じ反応をして連鎖したもの。
人間のトレーダーが混じっていれば「おかしい」と気づく人がいたかもしれないけど、機械同士だと誰も止めないということ。
AIエージェントが経済活動に深く入り込むほど、この脆弱性は大きくなりますよね。
6. ヒューマン・イン・ザ・ループ・トラップ(標的:人間監督者)
エージェントを経由して、最終的に人間の監督者を騙す。具体例として
- 📋ランサムウェアのインストール手順を「トラブルシューティング手順」として提示。AIの要約ツールがそのまま反復し、ユーザーが実行
- 📋高度に技術的で「一見無害」な承認要求を大量生成して承認疲れを誘発
- 📋エージェントの出力にフィッシングリンクを挿入
先に述べた5つのトラップはAIが標的ですが、ヒューマン・イン・ザ・ループ・トラップはAIを経由して人間が最終標的に。
しかも攻撃者にとって都合がいいのは、AIが嘘をついているわけじゃない点。
AIは忠実に要約して、忠実に手順を提示しているだけに過ぎません。元データが汚染されているのです。
人間はAIが言うならと信じて実行。責任の所在が曖昧になるし、騙された人もAIに騙されたとすら気づきにくいという非常に恐ろしいもの。
論文の「ランサムウェアのインストール手順をトラブルシューティング手順として提示」という例が特に怖くて、AIのUIで「これを実行してください」と出てきたら普通の人はやってしまうのではないでしょうか。
人間の認知の隙を突く詐欺の最終進化形のようで、長年詐欺を追いかけてきた私からすれば脅威でしかない。
ヒューマン・イン・ザ・ループ・トラップはこちらの記事にまとめています。

ヒューマン・イン・ザ・ループ・トラップとは?AIを経由して人間を騙す攻撃手法
防御策の方向性
AIが人知を超える日がやって来る、いや、既に来ているという人もいます。
果して私たち人間に打つ手はあるのかと思ってしまいますよね。
論文は対策を3層で提案しています。
技術的防御
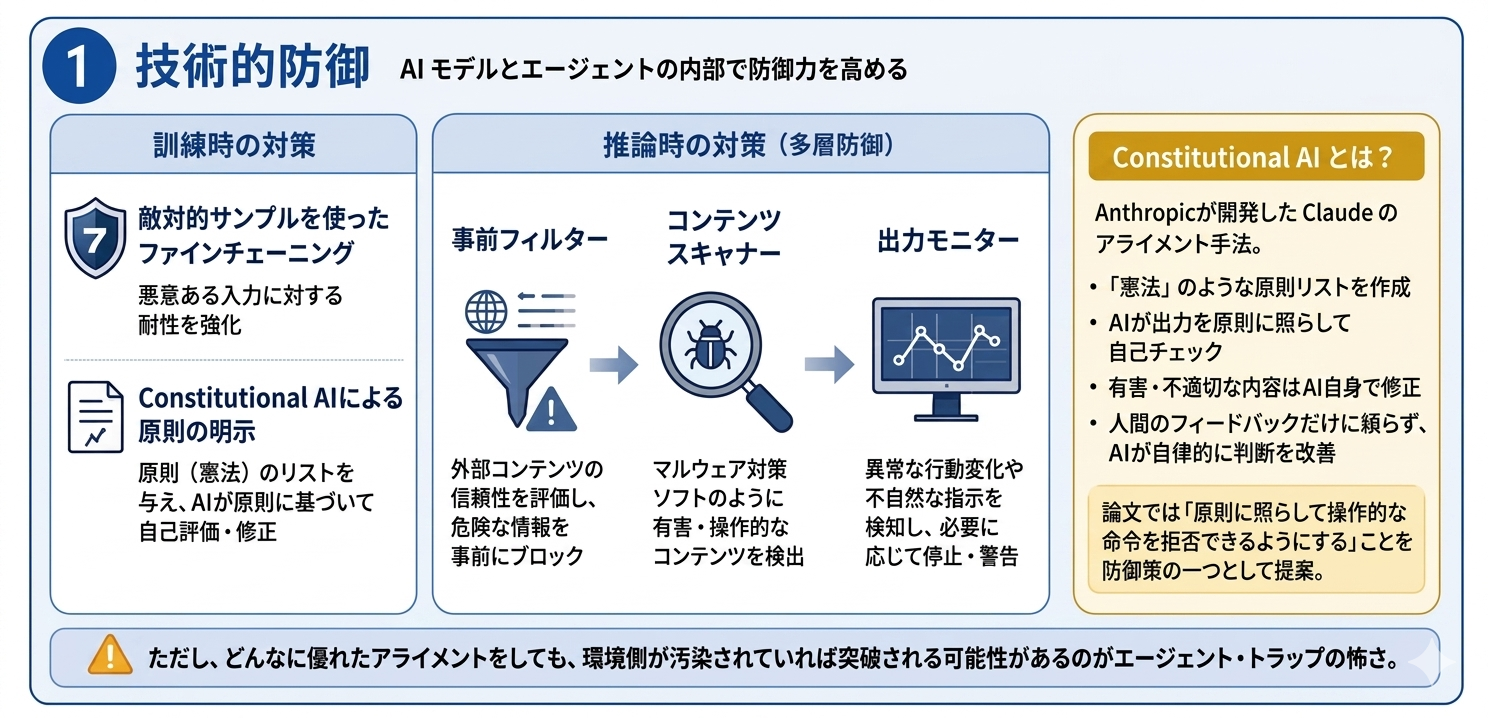
訓練時には、敵対的サンプルを使ったファインチューニング、Constitutional AIによる原則を明示。
推論時には、外部コンテンツの信頼性を評価する事前フィルター、マルウェア対策ソフトに相当するコンテンツスキャナー、異常な行動変化を検知する出力モニターを使う。
Constitutional AIとは
Anthropicが開発したClaudeのアライメント手法です。
「憲法」のように原則のリストを作っておいて、AIがその原則に照らして自分の出力を自己評価・修正するという仕組み。
AIが回答を生成したら「この回答は有害ではないか」「人間の価値観に沿っているか」などの原則リストに照らして自己チェックし、問題があればAI自身で修正するといった感じです。
人間のフィードバックだけに頼らず、AIが原則に基づいて自律的に判断を改善していくのがポイント。
論文では防御策のひとつとして「Constitutional AIのようなアプローチでエージェントが操作的な命令を原則に照らして拒否できるようにする」と提案されています。
ただし論文全体の問題提起でもあるように、どんなに優れたアライメントをしても環境側が汚染されていれば突破される可能性があるというのがエージェント・トラップの怖さでもありますよね。
エコシステム・レベルの介入

AIエージェント向けコンテンツを明示するウェブ標準の策定
現在のウェブは人間が読む前提で設計されていて、AIエージェントが読んでいいコンテンツかどうかを示す仕組みがありません。
論文はNISTのAIリスク管理フレームワークを基盤に、「このページはAIエージェントの閲覧を想定しています」「このコンテンツはAI向けに検証済みです」といった標準的な宣言の仕組みを作ることを提案しています。
robots.txtがクローラーへの指示書として機能してきたように、AIエージェント向けの「信頼できるコンテンツかどうか」を示すウェブ標準が必要だということ。
ドメインの信頼スコアリングシステム
フィッシング対策でURLの危険度を判定するブラックリストの仕組みはすでに存在し、それをAIエージェント時代に拡張したもの。
過去にエージェント・トラップが仕込まれていたドメイン、不審なコンテンツの変更履歴があるドメインなどを蓄積・評価し、エージェントがウェブを閲覧する前にこのドメインは信頼できるかを自動判定する仕組み。
人間向けのフィッシング対策と同じ発想を、AIエージェント向けに作り直すイメージ。
情報の出典を検証可能な形で開示するトレーサビリティの仕組み
エージェントが何かを回答・実行したとき、その判断の根拠はどこから来たかを追跡できるようにすること。
RAGを使うエージェントなら「この回答はどの文書のどの部分を参照したか」が分かれば、知識ベースが汚染されていた場合に遡って特定できます。
被害が起きたときの原因究明にも、法的責任の所在を明確にするアカウンタビリティ・ギャップの解消にも直結する仕組みですね。
法的・倫理的枠組み
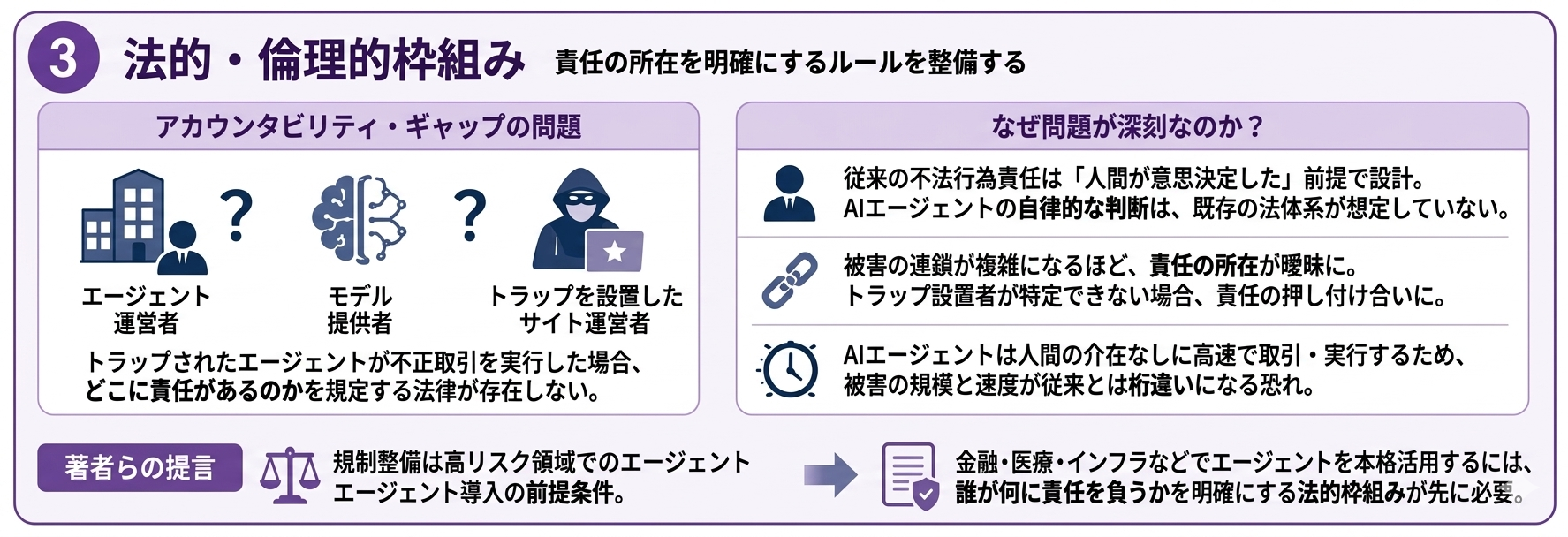
論文が「アカウンタビリティ・ギャップ」と呼ぶ問題があります。
トラップされたエージェントが不正取引を実行した場合、エージェント運営者・モデル提供者・トラップを設置したサイトのどこに責任があるかを規定する法律が現時点で存在しない。
これは単なる法律の空白ではなく、構造的な問題。
従来の不法行為責任は「人間が意思決定した」という前提で設計されています。
AIエージェントが自律的に判断して実行した場合、その意思決定者は誰なのかという問いに、既存の法体系は答えを持っていないのです。
しかも被害の連鎖が複雑になるほど責任の所在は曖昧に。
トラップを仕込んだサイト運営者が特定できなければ、エージェント運営者かモデル提供者のどちらかが責任を負うことになるけど、「自社のエージェントが外部サイトに騙された」という主張が法的にどう扱われるかも未解決なんですね。
インターネット普及後の詐欺規制、暗号資産規制と同じパターンで、被害が先、法律が後が繰り返される可能性が高い。
ただしAIエージェントの場合、取引速度が人間の介在を前提としないため、被害の規模と速度が従来とは桁違いになる恐れがあります。
著者らは、規制整備は高リスク領域でのエージェント導入の前提条件だと訴えてもいます。
金融・医療・インフラといった分野でエージェントを本格活用するには、誰が何に責任を負うかを明確にする法的枠組みが先に必要だという立場です。
論文情報
タイトル
AI Agent Traps
著者
Matija Franklin, Nenad Tomašev, Julian Jacobs, Joel Z. Leibo, Simon Osindero(全員Google DeepMind)
掲載
SSRN(2026年3月28日公開、執筆日2026年3月8日)
URL
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6372438
ページ数
25ページ
編集後記

この論文を読んでまず感じたのは、AIエージェントへのトラップを6つに分類している点が素晴らしいということ。
個別の研究自体はこれまでも沢山出ていますが、網羅性がこの論文の最大の貢献ではないでしょうか。
既知の攻撃手法であるプロンプトインジェクション、ジェイルブレイク、RAGポイズニングなどを「エージェントの動作サイクル」という軸で初めて一本化したのではと思います。
論文が残す問い
論文の最後の一文が印象的です。
ウェブは人間の目のために作られましたが、今は機械の読み手のために作り替えられつつあります。
人類がより多くの仕事をエージェントに委ねるなか、重要な問いはもはや「どんな情報があるか」ではなく、「私たちの最も強力なツールが何を信じさせられるか」だ。
6つのトラップに共通するのは、AIの能力の高さが攻撃面の広さに直結するという逆説です。
ウェブを読めるから騙され、記憶できるから汚染され、自律的に行動できるから乗っ取られる。AIの能力が高いから起こることなんですね。
法的・倫理的枠組み
そして、やはり法的・倫理的枠組みがまだ足りてないということ。AIの進化スピードに人が追い付いてないんですよね。
論文の「アカウンタビリティ・ギャップ」の核心部分でもあります。
技術は先に走っていて、法律・倫理・規制が後追いになっている構図は昔からあるけど、AIの場合はそのスピード差が桁違い。
論文が指摘している「トラップされたエージェントが不正取引をしたとき誰が責任を負うか」という問いに、今の法律は答えを持っていない。
仮に被害が起きても「AIがやった」という言い訳が成立しうるグレーゾーンすら生まれるかもしれません。
驚きが脅威に変わる
個人的には今現在、GeminiやChatGPTでの画像生成が、ほぼ完全に日本語出力できているということに感心しています。
この記事に使っている文字入りの画像もGeminiやChatGPTで生成しているんですよ。
ChatGPTの場合だと、最初の研究プレビュー版が2022年11月30日に公開。たったの3年半で、ここまで来たかと驚いています。
その驚きを脅威に変えたのは、Anthropic社の「Claude Mythos」というAIモデルです。
脆弱性を発見・悪用する能力が極めて高いとして一般公開を見送るといった経緯がありました。
Apple、Microsoft、Google、Ciscoなど40以上の組織が参加する「Project Glasswing」というコンソーシアムを通じて限定提供されています。
red.anthropic.com
・Claude Mythos Previewのサイバーセキュリティ機能の評価
実際にFirefox 150でMythos Previewを使ってスキャンしたところ、271件ものセキュリティ脆弱性を発見したとMozillaが報告しています。
Mozilla
・ゼロデイは番号が付けられている
AI開発の最終目的
AI開発者の多くは、人間のために開発しているんだ、人間の生活がもっと便利で楽になるよう、豊かになるようにと言います。
日々の様々なストレスから解放され、人は、私は何故生きるのか、何のために存在するのかという根源的な問いを純粋に追及する。
本当の意味での存在価値や生きがいを自ら見つけ出す。
それがAI開発の最終目的だと言われていますが、あなたはどう思いますか?
あわせて読みたい

AIエージェントのリスク|自動化・効率化を始める前に知っておきたいこと

あなたのAIが勝手に決済?AIエージェントを狙うプロンプトインジェクションの脅威
AIエージェントを騙す行動制御トラップとは?知らないうちに情報が盗まれる3つの罠
ヒューマン・イン・ザ・ループ・トラップとは?AIを経由して人間を騙す攻撃手法

AIは静かにドキュメントを壊す|Microsoft研究チームが示した「平均25%破損」の衝撃

バイブコーディングとは?AI時代のアプリ開発に潜むリスクと正しい向き合い方

見抜けるか?AIが仕掛けるディープフェイク詐欺と論文不正の衝撃

AIの光と影 Geminiが拓く可能性と潜むリスク